
 摘要:
英特尔广泛的AI硬件组合及开放的软件环境,为Meta发布的Llama2模型提供了极具竞争力的选择,进一步助力大语言模型的普及,推动AI发展惠及各行各业。大语言模型(LLM)在生成...
摘要:
英特尔广泛的AI硬件组合及开放的软件环境,为Meta发布的Llama2模型提供了极具竞争力的选择,进一步助力大语言模型的普及,推动AI发展惠及各行各业。大语言模型(LLM)在生成... 微信号
15618884964
英特尔广泛的AI硬件组合及开放的软件环境,为Meta发布的Llama2模型提供了极具竞争力的选择,进一步助力大语言模型的普及,推动AI发展惠及各行各业。
大语言模型(LLM)在生成文本、总结和翻译内容、回答问题、参与对话以及执行复杂任务(如解决数学问题或推理)方面表现出的卓越能力,使其成为最有希望规模化造福社会的AI技术之一。大语言模型有望解锁更丰富的创意和洞察,并激发AI社区推进技术发展的热情。
Llama2旨在帮助开发者、研究人员和组织构建基于生成式AI的工具和体验。Meta发布了多个Llama2的预训练和微调版本,拥有70亿、130亿和700亿三种参数。通过Llama2,Meta在公司的各个微调模型中采用了三项以安全为导向的核心技术:安全的有监督微调、安全的目标文本提取以及安全的人类反馈强化学习(RLHF)。这些技术相结合,使Meta得以提高安全性能。随着越来越广泛的使用,人们将能够以透明、公开的方式不断识别并降低生成有害内容的风险。
英特尔致力于通过提供广泛的硬件选择和开放的软件环境,推动AI的发展与普及。英特尔提供了一系列AI解决方案,为AI社区开发和运行Llama2等模型提供了极具竞争力和极具吸引力的选择。英特尔丰富的AI硬件产品组合与优化开放的软件相结合,为应对算力挑战提供了可行的方案。
英特尔提供了满足模型的开发和部署的AI优化软件。开放生态系统是英特尔得天独厚的战略优势,在AI领域亦是如此。我们致力于培育一个充满活力的开放生态系统来推动AI创新,其安全、可追溯、负责任以及遵循道德,这对整个行业至关重要。此次发布的大模型进一步彰显了我们的核心价值观——开放,为开发人员提供了一个值得信赖的选择。Llama2模型的发布是我们行业向开放式AI发展转型迈出的重要一步,即以公开透明的方式推动创新并助力其蓬勃发展。
--李炜
英特尔软件与先进技术副总裁
兼人工智能和分析部门总经理
--MelissaEvers
英特尔软件与先进技术副总裁
兼执行战略部总经理
在Llama2发布之际,我们很高兴地分享70亿和130亿参数模型的初始推理性能测试结果。这些模型在英特尔AI产品组合上运行,包括Habana?Gaudi?2深度学习加速器、第四代英特尔?至强?可扩展处理器、英特尔?至强?CPUMax系列和英特尔?数据中心GPUMax系列。我们在本文中分享的性能指标是我们当前软件提供的“开箱即用”的性能,并有望在未来的软件中进一步提升。我们还支持700亿参数模型,并将很快分享最新相关信息。
Habana?Gaudi?2深度学习加速器
HabanaGaudi2旨在为用户提供高性能、高能效的训练与推理,尤其适用于诸如Llama和Llama2的大语言模型。Gaudi2加速器具备96GBHBM2E的内存容量,可满足大语言模型的内存需求并提高推理性能。Gaudi2配备Habana?SynapseAI?软件套件,该套件集成了对PyTorch和DeepSpeed的支持,以用于大语言模型的训练和推理。此外,SynapseAI近期开始支持HPUGraphs和DeepSpeed推理,专门针对时延敏感度高的推理应用。Gaudi2还将进行进一步的软件优化,包括计划在2023年第三季度支持FP8数据类型。此优化预计将在执行大语言模型时大幅提高性能、吞吐量,并有效降低延迟。
大语言模型的性能需要灵活敏捷的可扩展性,来突破服务器内以及跨节点间的网络瓶颈。每张Gaudi2芯片集成了21个100Gbps以太网接口,21个接口专用于连接服务器内的8颗Gaudi2,该网络配置有助于提升服务器内外的扩展性能。
在近期发布的MLPerf基准测试中,Gaudi2在大语言模型上展现了出色的训练性能,包括在384个Gaudi2加速器上训练1750亿参数的GPT-3模型所展现的结果。Gaudi2经过验证的高性能使其成为Llama和Llama2模型训练和推理的高能效解决方案。
图1显示了70亿参数和130亿参数Llama2模型的推理性能。模型分别在一台HabanaGaudi2设备上运行,batchsize=1,输出token长度256,输入token长度不定,使用BF16精度。报告的性能指标为每个token的延迟(不含第一个)。该测试使用optimum-habana文本生成脚本在Llama模型上运行推理。optimum-habana库能够帮助简化在Gaudi加速器上部署此类模型的流程,仅需极少的代码更改即可实现。如图1所示,对于128至2000输入token,在70亿参数模型上Gaudi2的推理延迟范围为每token9.0-12.2毫秒,而对于130亿参数模型,范围为每token15.5-20.4毫秒1。
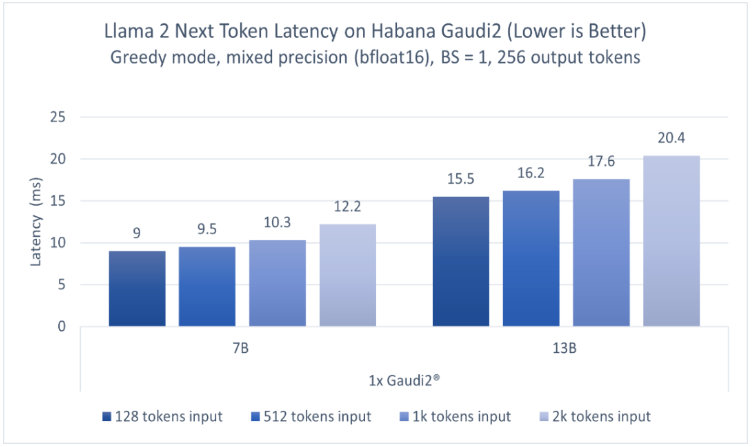
若想访问Gaudi2,可按照此处(https://developer.habana.ai/intel-developer-cloud/)在英特尔开发者云平台上注册一个实例,或联系超微(Supermicro)了解Gaudi2服务器基础设施。
英特尔?至强?可扩展处理器
第四代英特尔至强可扩展处理器是一款通用计算处理器,具有英特尔?高级矩阵扩展(英特尔?AMX)的AI加速功能。具体而言,该处理器的每个核心内置了BF16和INT8通用矩阵乘(GEMM)加速器,以加速深度学习训练和推理工作负载。此外,英特尔?至强?CPUMax系列,每颗CPU提供64GB的高带宽内存(HBM2E),两颗共128GB,由于大语言模型的工作负载通常受到内存带宽的限制,因此,该性能对于大模型来说极为重要。
目前,针对英特尔至强处理器的软件优化已升级到深度学习框架中,并可用于PyTorch*、TensorFlow*、DeepSpeed*和其它AI库的默认发行版。英特尔主导了torch.compileCPU后端的开发和优化,这是PyTorch2.0的旗舰功能。与此同时,英特尔还提供英特尔?PyTorch扩展包*(Intel?ExtensionforPyTorch*),旨在PyTorch官方发行版之前,尽早、及时地为客户提供英特尔CPU的优化。
第四代英特尔至强可扩展处理器拥有更高的内存容量,支持在单个插槽内实现适用于对话式AI和文本摘要应用的、低延迟的大语言模型执行。对于BF16和INT8,该结果展示了单个插槽内执行1个模型时的延迟。英特尔?PyTorch扩展包*支持SmoothQuant,以确保INT8精度模型具有良好的准确度。
考虑到大语言模型应用需要以足够快的速度生成token,以满足读者较快的阅读速度,我们选择token延迟,即生成每个token所需的时间作为主要的性能指标,并以快速人类读者的阅读速度(约为每个token100毫秒)作为参考。如图2、3所示,对于70亿参数的Llama2BF16模型和130亿参数的Llama2INT8模型,第四代英特尔至强单插槽的延迟均低于100毫秒2。
得益于更高的HBM2E带宽,英特尔至强CPUMax系列为以上两个模型提供了更低的延迟。而凭借英特尔AMX加速器,用户可以通过更高的批量尺寸(batchsize)来提高吞吐量。
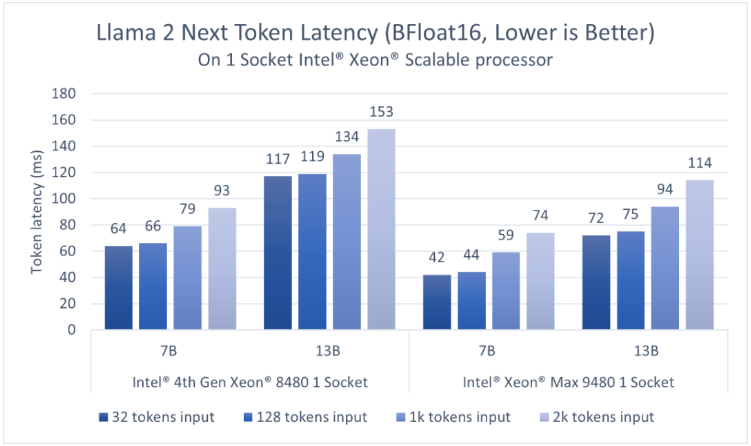
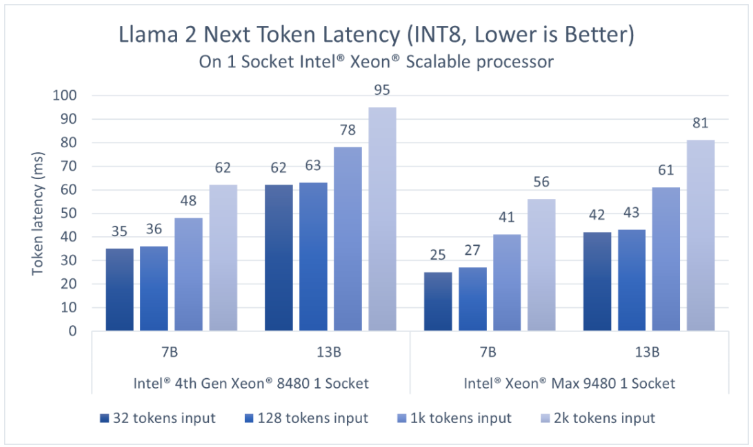
对于70亿和130亿参数的模型,每个第四代至强插槽可提供低于100毫秒的延迟。用户可以分别在两个插槽上同时运行两个并行实例,从而获得更高的吞吐量,并独立地服务客户端。亦或者,用户可以通过英特尔?PyTorch扩展包*和DeepSpeed*CPU,使用张量并行的方式在两个第四代至强插槽上运行推理,从而进一步降低延迟或支持更大的模型。
关于在至强平台上运行大语言模型和Llama2,开发者可以点击此处(https://intel.github.io/intel-extension-for-pytorch/llm/cpu/)了解更多详细信息。第四代英特尔至强可扩展处理器的云实例可在AWS和MicrosoftAzure上预览,目前已在谷歌云平台和阿里云全面上线。英特尔将持续在PyTorch*和DeepSpeed*进行软件优化,以进一步加速Llama2和其它大语言模型。
英特尔?数据中心GPUMax系列
英特尔数据中心GPUMax系列提供并行计算、科学计算和适用于科学计算的AI加速。作为英特尔性能最为出色、密度最高的独立显卡,英特尔数据中心GPUMax系列产品中封装超过1000亿个晶体管,并包含多达128个Xe内核,Xe是英特尔GPU的计算构建模块。
英特尔数据中心GPUMax系列旨在为AI和科学计算中使用的数据密集型计算模型提供突破性的性能,包括:
●408MB基于独立SRAM技术的L2缓存、64MBL1缓存以及高达128GB的高带宽内存(HBM2E)。
●AI增强型的Xe英特尔?矩阵扩展(英特尔?XMX)搭载脉动阵列,在单台设备中可实现矢量和矩阵功能。
英特尔Max系列产品统一支持oneAPI,并基于此实现通用、开放、基于标准的编程模型,释放生产力和性能。英特尔oneAPI工具包括高级编译器、库、分析工具和代码迁移工具,可使用SYCL轻松将CUDA代码迁移到开放的C++。
英特尔数据中心Max系列GPU通过当今框架的开源扩展来实现软件支持和优化,例如面向PyTorch*的英特尔扩展、面向TensorFlow*的英特尔?扩展和面向DeepSpeed*的英特尔?扩展。通过将这些扩展与上游框架版本一起使用,用户将能够在机器学习工作流中实现快速整合。
我们在一个600瓦OAM形态的GPU上评估了Llama2的70亿参数模型和Llama2的130亿参数模型推理性能,这个GPU上封装了两个tile,而我们只使用其中一个tile来运行推理。图4显示,对于输入长度为32到2000的token,英特尔数据中心GPUMax系列的一个tile可以为70亿参数模型的推理提供低于20毫秒的单token延迟,130亿参数模型的单token延迟为29.2-33.8毫秒3。因为该GPU上封装了两个tile,用户可以同时并行运行两个独立的实例,每个tile上运行一个,以获得更高的吞吐量并独立地服务客户端。
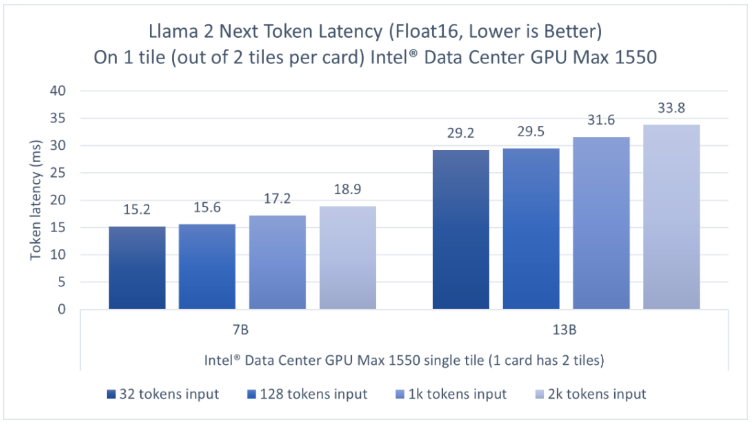
关于在英特尔GPU平台上运行大语言模型和Llama2,可以点击此处(https://intel.github.io/intel-extension-for-pytorch/llm/xpu/)获取详细信息。目前英特尔开发者云平台上已发布英特尔GPUMax云实例测试版。
英特尔平台上的大语言模型微调
除了推理之外,英特尔一直在积极地推进微调加速,通过向HuggingFaceTransformers、PEFT、Accelerate和Optimum库提供优化,并在面向Transformers的英特尔?扩展中提供参考工作流。这些工作流支持在相关英特尔平台上高效地部署典型的大语言模型任务,如文本生成、代码生成、完成和摘要。
总结
上述内容介绍了在英特尔AI硬件产品组合上运行Llama2的70亿和130亿参数模型推理性能的初始评估,包括HabanaGaudi2深度学习加速器、第四代英特尔至强可扩展处理器、英特尔?至强?CPUMax系列和英特尔数据中心GPUMax系列。我们将继续通过软件发布提供优化,后续会再分享更多关于大语言模型和更大的Llama2模型的评估。
微信号
15618884964







